Preface by Lorenzo Bianchi Chignoli
These lecture notes were originally prepared for the Topics in Macroeconomics II. Expectation and Optimal Policy course offered by Albert Marcet in the MRes in Economics program at Universitat Pompeu Fabra during the Fall 2025 term. The content is primarily derived from my personal notes. Many of the mathematical derivations were worked out as exercises and, therefore, may contain inaccuracies.
This course explores modelling approaches to expectations, and the corresponding optimal policies in dynamic economies. The two main sections of the notes reflect this structure.
Expectations
History of Rational Expectations
Older approaches simply specified expectations as a fixed functions of current and previous variables, rather than forward looking expectations based on the model’s own laws. Assuming inconsistent expectations to the model’s implication is the most disappointing feature of the non-rational expectations paradigm. The crisis of Classical Keynesian models occurred in the 70s with the failure of the classical Phillips Curve to predict a positive correlation between inflation and unemployment. With rational expectations (hereafter, RE), instead, agent’s predictions coincide with the objective model’s predictions. This also implies that expectations are enforced by the model itself: there is no additional degrees of freedom to test the model predictions against specifications of expectations. Sure enough, the Classical Keynesian models had an excessive, basically infinite amount of degrees of freedom, with maximized explanatory power and minimized predictive power. At that time, RE was a welcome methodological innovation, as it avoided arbitrary model specifications.
Agents in the Old Keynesian models were assumed to form expectations following equations that differed from the model’s equation determining the very outcome expected upon. Put simply, Old Keynesian agents make the same mistake all the time. In contrast, real-world agents do make mistakes, but these are not identical at all times, and do not incur systematic welfare losses due to misspecified expectations. Put simply, Classical Keynesian models were lacking a learning mechanism for people to adjust their expectational equations.
RE, instead, avoided that “stupid” mistakes were repeatedly committed, and became the dominant paradigm in modelling expectations in economics around the 80s. This is thanks to some theoretical features of RE:
- The choice of expectations is dictated by the model, and no arbitrary modelling is admitted.
- It a stable expectation that is maintained in the long run
- It prevents agents to make systematic, or even “stupid”, mistakes in their forecasts. Although these are good methodological justification, and any deviation from RE should address them, it seems like an unreasonable burden that agents come to know rational expectations straight away. Moreover, alternative way to solve such problems may exist.
An Application: Expectations and Asset Prices
An excellent example for modeling expectation is the stock market. Stock prices are quite unpredictable, especially in the long run, where booms and busts dominate the pricing dynamics. The stock market may exhibit high prices either due to good fundamentals, and the corresponding well-grounded expectations of profitability; or mistaken expectations, which may lead to a bubble burst. The conflict between expectations and outcomes is well exemplified by the famed excess return regressions. Fama’s efficient market’s hypothesis should prevent agents from predicting stock prices (read as: to find a large and statistically significant value for a coefficient in the regression of stock prices).
The Efficient Market Hypothesis
The primary role of the capital market is allocation of ownership of the economy’s capital stock. In general terms, the ideal is a market in which prices provide accurate signals for resource allocation: that is, a market in which firms can make production-investment decisions, and investors can choose among securities that represent ownership of firms’ activities under the assumption that security prices at any time ‘fully reflect’ all available information. A market in which prices always ‘fully reflect’ available information is called ‘efficient’. (Fama, 1970, p. 383)
Instead, excess return regressions show this is not quite the case. Consider Table 1 in Adam, Marcet, Nicolini:
| Quantity | Coefficient | Other measure |
|---|---|---|
| Volatility of PD ratio | ||
| Persistence of PD ratio | ||
| Excessive return volatility | ||
| Excess long run return predictability ( years) | ||
| Equity premium |
where denotes dividends, stock prices, is the price-dividend ratio, and are the returns for stocks and bonds. This shows that stock prices are highly volatile: not only the standard deviation of the price-to-dividend ratio is extremely high relative to its mean, but also the standard deviation in stock returns are much larger than the standard deviation in dividends. Moreover, fluctuations in PD are persistent. Put simply: If markets are efficient, stock prices () should only move when there is news about the future cash flows (dividends, ). Therefore, the price-dividend ratio () should be relatively stable unless expected future dividend growth changes, and returns should be unpredictable. Instead, the data shows the ratio is incredibly volatile ( is high) and persistent (it stays high or low for a long time). Moreover, prices move around much more than dividends do.
This leads to the famed long run return predictability, incorporated in the excess return regressions (Fama and French, 1992). The test (which is reported in Cochrane’s version) works as follows: When the ratio moves, what happens next? Does it predict that dividends will change? Or does it predict that prices will snap back (mean reversion)? The regressions show that today’s ratio does not predict future dividends (which would be the “efficient” explanation); instead, it predicts future returns. Then, high volatility in prices is not driven by fundamentals (dividends), but rather by fluctuations in expected returns. Prices swing away from fundamentals and then slowly revert back, creating predictable excess returns. Formally, define the total future -period excess returns as
and run the following regressions:
Empirical results for this regression are provided by Cochrane (2005) as follows:
| Predict | Predict | |||||
|---|---|---|---|---|---|---|
| 1 | 5.30 | 2.00 | 0.15 | 2.00 | 1.10 | 0.06 |
| 2 | 10 | 3.10 | 0.23 | 2.50 | 2.1 | 0.06 |
| 3 | 15 | 4.00 | 0.37 | 2.4 | 2.1 | 0.06 |
| 5 | 33 | 5.80 | 0.6 | 4.7 | 2.4 | 0.12 |
(Beware that this data has DP rather than PD on the RHS, and data is yearly rather than quarterly like in the previous table.) Put simply, future excess returns are higher when is low (relative to the dividend it yields). Moreover, is significantly different from 0, the more the longer the horizon . Finally, the is relatively high and rejects the “weak form of market efficiency” in the long run. This result is very robust and is sometimes described as mean reversion of DP. In contrast, is not significant: therefore, mean reversion and volatility of returns are due to price movements, and not dividends.
Let us attempt to micro-found asset pricing with RE. In the famed model by Lucas and Stokey, a representative consumer/investor chooses stock holdings and consumption to solve:
with exogenous . The stock market is competitive, with a total (normalized) supply of 1. Feasibility is ensured at and the stock market equilibrium implies (the RA demand equals supply). The FOC for the optimal is:
which can be plugged into the equilibrium conditions. By forward iteration and LIE (after assuming bounded prices):
Given that consumption is fixed by the feasibility condition, in equilibrium this expectation is a function of past ‘s only. Notice that in principle the that solves investors’ problem should be a function of past stock demand; however, stock holdings are not a state variable on equilibrium. More formally, for a history profile , it holds that prices should be predicted as a function of exogenous processes up to history time , with no role of prices in predictions:
for some non-stochastic pricing function .
However, Cochrane’s (2005) regressions show that it is virtually possible to “predict the future”: high prices systematically accompany price drops (recall, the ratio is dividend-to-prices in Cochrane’s regressions). Positive, but not significant, results are also obtained for dividends predictions. Thus, something is much strongly incorporated in prices that in cash flows — that is, actual profitability. Something else might affect this difference, as the fundamental does not seem to suffice. Moreover, the model assumes that agents actually know the non-stochastic pricing function since their birth. The only uncertainty lies in the stochastic process for the exogenous variables.
Assuming RE leads to serious puzzles once we get to the data. For instance, the equity premium puzzle (Mehra and Prescott, 1982), and especially Shiller’s (1981) excess volatility puzzle. Both phenomena are difficult to explain through rational expectations. Intuitively, the reasons is that under RE it is in general difficult to explain stock prices volatility in the equation
In fact, averaging dividends (twice: the expectation is a probabilistic average, over a time series which also serves as an average) implies that volatility should drop dramatically. If this equation would hold, then, it would be unlikely that prices are more volatile than dividends. For precision, consider the risk neutral case to give a structural form to marginal utilities, with no labor income. Assume that dividends follow a pure unit root process such as with error with mean 1. Prices are a discounted sum of the future stream of dividends:
Substituting (and ignoring variance terms in a loglinear approximation):
which implies that the ratio is constant. This contradicts data dramatically, where the ratio is highly volatile.
In the subsequent twenty years, many authors actually provided success stories in their attempt to generalize Lucas’ asset pricing model, for instance with more general utility functions, production functions, incomplete markets, heterogeneous agents, and the like. For years, they failed repeatedly to give a quantitative explanation. Some exceptions include the following cases.
Campbell and Cochrane (1999) focus on habits, and defined the utility function:
where the stochastic discount factor depends on . Since this is highly volatile, this affects the risk aversion which becomes . However, this utility function leads to weird results when plugged into standard DSGE models, such as increased utility for decreasing consumption. Because agents care about the gap (relative status), not the absolute amount, they are mathematically happier being poor in a society where everyone else is destitute (low habit), than being rich in a society where everyone else is slightly richer (high habit)1. Ljungqvist and Uhlig showed that in these models, a government could theoretically burn 10% of the country’s endowment and make everyone happier by ending the “rat race”.
Bansal and Yaron (2004) assume output growth has a slow-moving component that affects dividends, such as such that . Importantly, is perfectly observed by investors in period . Since is the denominator and , small changes in lead to large changes in prices. This allows to explain the variance in the data. However, some problems still persist. To match, the data, the variance of should be very small, because dividend growth does not show a strong unit root behavior in practice. If the variance of is much smaller than the variance of , then this will assume a huge role as it piles up in the long run. The growth rate becomes time-varying and can exhibit large fluctuations; moreover, since the denominator is close to 1, small fluctuations in lead to large fluctuations in the growth rate. Yet, it is weird to assume that agents in the model know about a variable, , which does not even exist in statistical agencies.
Last, the rare disasters literature is also an example of success of RE. In this case, : a small probability multiplies a very large number; then, taking the variance of consumption does not provide good insights on the variance of marginal utility, that could explode due to rare disasters. The main criticism, however, sounds as follows: if the truth is that these “small perceived probabilities” matter so much for asset pricing, then how can we ever know anything about stock price behavior? This is very close to a purely behavioral story where agents’ arbitrary changes in expectations can matter a lot.
Summing up, these attempt are starting to resonate familiar with the late-70s strategy. It is always possible to cook up models where a flawed assumption can explain some phenomena ex post, despite being basically useless for ex ante prediction. Moreover, survey data suggest that even professional forecasters are not following RE that explain the evolution of quantities such as the PD ratio (Adam, Marcet and Beutel, AER 2017). RE is not the only way to attain the objectives desired by Sargent, Prescott, Lucas, and many others. With the additional contribution of the GFC, non-RE are being liberalized in these years, although this still faces a strong resistance. In fact, a mainstream argument is that departures from RE should be temporary — any learning feature should converge rapidly to RE. This is usually referred to as the Friedman hypothesis.
Market Selection Hypothesis or Friedman Hypothesis
Investors that hold wrong beliefs will be driven out of the market very quickly.
However, recent evidence suggests that not only learning, but also expulsion from the market takes a lot of time. Moreover, overly optimistic “crazy” agents may be overly parsimonious, and their savings may still ferry them to the future market (despite present welfare losses).
A formal test of RE through surveys
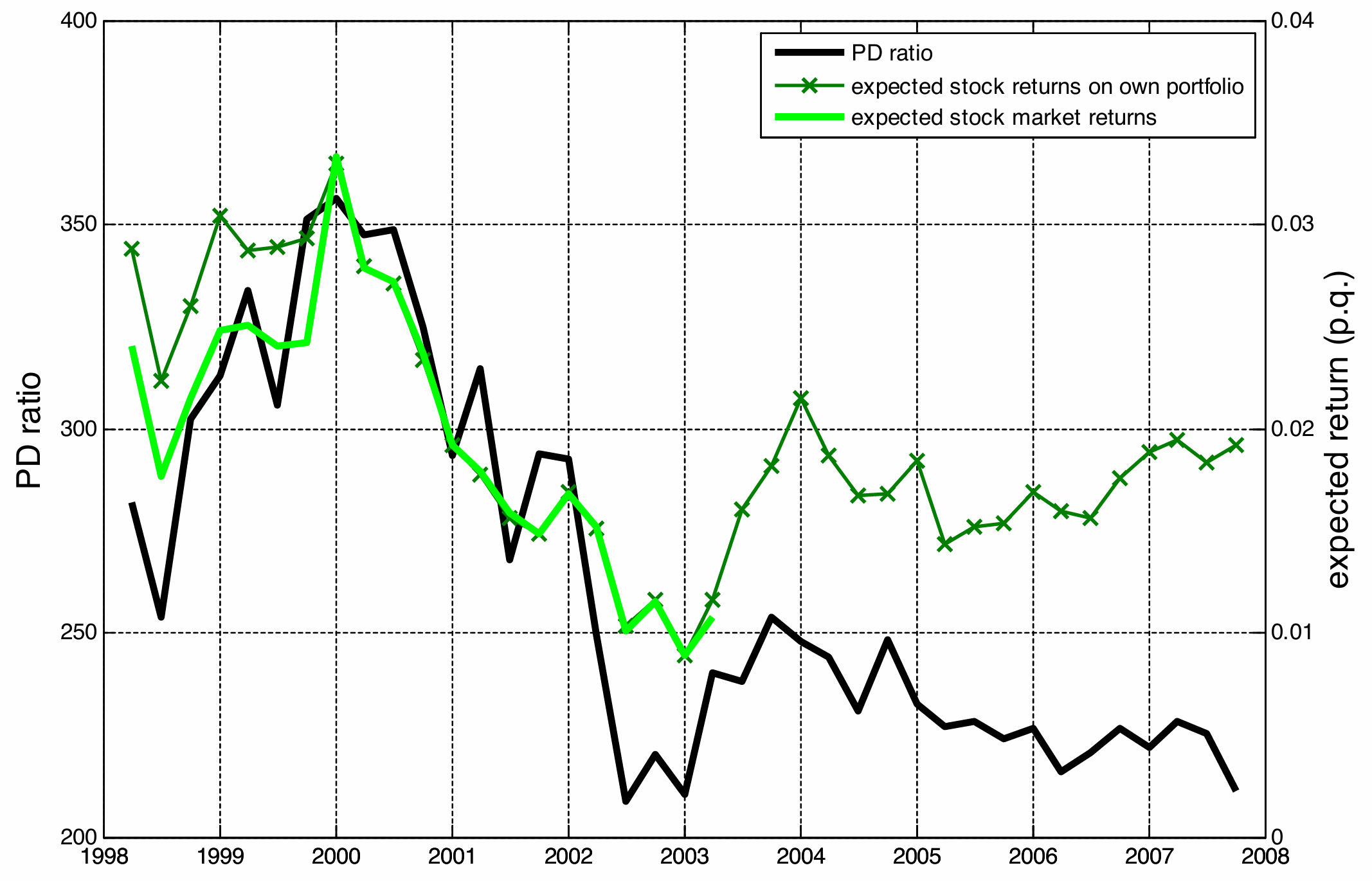
This graphs shows the median stock returns over investors that answers the survey, and should represent the “consensus belief”. Investors were most optimistic about stock returns at the top of the dot.com bubble (December, 1999). However, excess return regressions would have suggested that future returns were on average low at the top of the bubble (that is, high PD). Put simply, the green line in the graph seems incompatible with both RE among investors and data-driven prediction of the excess return regressions. Note that this plot suggest a positive correlation between PD and expected returns:
| Survey | Correlation |
|---|---|
| UBS Gallup 1yr | .79 |
| Shiller Survey 1yr | .38 |
| Shiller Survey 10yr | .66 |
while their empirical correlation is negative!
It is possible to utilize a formal test for the idea that investors’ expectations do not instance RE nor excess-return ideas (Adam, Marcet and Beutel, 2017). Observed expectations are defined as where the first term represents expectations and is a measurement error (agents might also report inconsistently, as they might not be sure about their opinions). The test constructs a comparison between expectations and reality. It shows that investors are not rational because they are pro-cyclical (optimistic when prices are high) while the actual market is counter-cyclical (returns are low when prices are high). This is why the notes state that “a good model should match these variables, but this is not the case” for RE models. Define:
- Survey expectations, This is the subjective expected return coming from surveys (e.g., the UBS/Gallup survey or Shiller’s survey) where they ask investors: “How much do you expect the stock market to return over the next year?“. It should incorporate the relationship: .
- Realized returns, . This is the objective actual return that occurred in the market over that same period. is the true mathematical expectation.
Regress:
to find an estimate . Then, regress:
to find an estimate . Under RE, these should be identical, since the residual should still be orthogonal to the regressions. In fact, plugging in for the true expectation into ^1177f5:
for the true prediction error . Clearly, because is a regression error, is a measurement error assumed as orthogonal, and is a “true” forecasting error. The hypothesis can be tested by SURE and is, in fact, rejected:
| Survey measure | p value | ||
|---|---|---|---|
| UBS*, all, 1yr, Michigan | 0.53 | -2.93 | 0.0000 |
| Shiller, 1yr, Michigan | 0.28 | -1.48 | 0.0000 |
| Shiller, 10yr, Michigan | 3.51 | -6.48 | 0.0000 |
This regression also allows to attempt model matching. A good model should match there variables, but this is not the case: they even have opposite signs.
- Reality (): When is high (market is expensive), future returns are low (mean reversion).
- Beliefs (): When is high (market is expensive), investors expect future returns to be high.
A similar test was developed by Coibion and Gorodnichenko as:
or similarly
where the null (rejected) is . The test is identical to AMB, since .
Asset Prices under Bayesian-RE and Disagreement
Learning about Fundamental shocks
In Bayesian models, agents do not know all the moments of the fundamental data generating process. In this section, we analyze a model of learning about fundamental shocks. This model is interesting to explore if Bayesian RE converge to RE, and if so how fast, and whether Bayesian RE can be used as a bounded substitute for RE.
Consider a special case of Lucas’ model with no risk aversion and . The growth rate of dividends follows with mean zero error. Under RE, this case implies . Therefore, under RE:
which implies a constant PD ratio.
Let us now introduce learning about dividends in this special case. Assume agents don’t know the value of , but have an initial belief about the growth rate such as:
Other than this, they know that follows the process described in ^2a7dd9. Agents have a fully consistent model of dividends and they use this to evaluate their utility. The only deviation from Lucas’ model is that investors maximize the expectation given agents’ imperfect knowledge about the dividend process, . Thus, agents do not maximize the true distribution, and rather the distribution conditional on their imperfect knowledge about the dividend process. For a perspective, this is equivalent to . Given the information at , this is equivalent to , where , where denotes the random variable representing the hidden trend in the Kalman filter. Thus, optimal behavior implies:
To compute this, remember that agents know the likelihood of but don’t know . Since they know the model:
By error with zero mean, . Taking an approximation, , so that:
To find in a general setup, we resort to the Kalman filter. A summary is provided below.
The Kalman Filter
Consider a multivariate system:
with zero-mean errors. The perceived distribution for initial (the prior, ) is fixed. All parameters and the distributions of the errors are known. While is the unobserved “true” state, is the observed signal, which we must forecast based on previous values. Note that for a history . Therefore, the problem boils down to finding . In a general, non-linear setup we should keep track of the entire posterior distribution of , and all previous values in history would be needed to formulate . In the Kalman filter, however, the formula for is recursive under the following assumptions:
- Parameters are known, together with the linear law of motion in ^fba960
- are Gaussian with known variances
- The initial perceived distribution is also Gaussian: If these hold, then is a function of and .
For the univariate case (in particular, the ^4c17be), the optimal forecasts are given by:
where
For illustration, consider these cases:
- Case 1: and . In this case, is a constant and we have no prior knowledge, as in classical econometrics. Then, one can work out that the previous formulae yield and , the simple sample average.
- Case 2: , as in Bayesian econometrics. Then, is the Bayesian posterior mean.
- Case 3: and , as in time varying VARs. That is, is an unobserved time-varying ex ante growth rate that follows a unit root process. In this case, it holds that the gain , where the latter solves:
Most papers take this relationship in the long run and consider ^ccc7ed as:
so that is a geometric average of its past values. The steady state gain is lower for a higher , meaning that if the transitory shock has higher variance, less weight is put on recent observations.
Disagreement
Once we consider deviations from RE, we open the door to considering different perceptions across investors: disagreement. The paper by Vissing-Jorgensen (2004) reports the standard deviation of expected returns across investors interviewed in the survey. Disagreement is large and, interestingly, larger at the peak of the dot.com bubble. Many papers find similar patterns for other periods and other assets.
Consider a Lucas’ model with two heterogeneous agent RE, where the source of heterogeneity lies in the discount factor, which is individual-specific. Each household maximizes:
In a complete market, agents can trade contracts for every possible future state of the world, which allows them to share risk perfectly. When markets are complete, the First Welfare Theorem applies, and the competitive equilibrium is Pareto-efficient. The FOCs are:
The problem can be solved from the perspective of a planner with Pareto weights without prices of bonds2:
with FOC:
this FOC, combined with the feasibility condition, allows to solve for the s. So, given some , each consumption path is a fixed function of total output , and the pricing equation finally yields .
So far, we assumed that agents are homogeneous, apart from the following:
- Different leading to full risk sharing. Moreover, if are CRRA with same RRA coefficient, prices are just the same as if there were a unique representative agent (see ^65722f which implies Gorman aggregation as a specific case).
- Different utility. Suppose is concave, but . Then, agent 2 perfectly insures agent 1.
- Different discount factors. If , then . However, in all these cases, both agents affect the pricing of the stock.
Things change when agents disagree about how to forecast . For simplicity, assume that agents are otherwise homogeneous, and focus on Markov models where the conditional density is for a time-invariant function . In particular, denote . The density or likelihood of the observed sample is, thus, . Now, assume that investor knows that is Markov, but they maintain individual forecasting functions for the divided and wage processes, that is . To the extent that , RE are obviously not satisfied. To the extent that , disagreement takes place. Now, ‘s utility is given by where is computed with . From a general equilibrium standpoint, the fact that the two agents hold different expectations is just equivalent to a case where agents have different utility. Then, the FPWF and SPWF continue to hold under complete markets. Put simply, disagreement does not break the Arrow-Debreu theorem, since different probabilities attached to future states can be incorporated in the utility function, and the Arrow-Debreu theorem only relies on utility functions, regardless that such utility functions differ. Competitive equilibrium solves:
for some Pareto weight . The planner FOC is as follows:
and can be combined into a unique condition by equating the :
An important result is that disappearance from the market is very slow, basically contradicting the Friedman hypothesis. Advocates for the Friedman hypothesis normally invoke agents who are completely mistaken, or Aumann’s “common knowledge” assumptions. In the first case, agents who attach subjective probability equal to 0 to some state belonging to the support are very quickly expelled from the market. This is because they bet effectively infinite odds against an event that eventually occurs, leading to immediate bankruptcy. In the second case, which relies on Aumann’s agreement theorem or the Blackwell-Dubins result on the “merging of opinions,” agents share common priors and the information structure is common knowledge. In this framework, disagreements are impossible to sustain: agents either instantly converge to the truth or, recognizing the rationality of others, refuse to engage in speculative trade (Milgrom and Stokey (1982) no trade theorems). Here, market efficiency is an assumption of the setup, not a result of evolutionary selection. However, the Friedman hypothesis is wrong in general. If agents have beliefs that are wrong but “absolutely continuous” with respect to the truth (i.e., they assign positive probability to all possible events), and they do not share common priors, they can survive and influence prices for extremely long periods. Consider the case with a mistaken agent and compute the expectation:
Since the ratio satisfies the martingale property (as shown in the derivation), we can take the limit as . By the Martingale Convergence Theorem, the random variable must converge to a limit almost surely. If agent 2 is correct (uses the true measure) and agent 1 is “mistaken” (in the sense that their Kullback-Leibler divergence from the truth is positive), then the likelihood ratio of the true agent to the false agent explodes:
Using the Planner’s FOC, this implies that the ratio of marginal utilities must also explode:
For this ratio to go to infinity, the denominator (agent 1’s marginal utility) stays finite, which forces the numerator (agent 2’s marginal utility) to infinity:
While the math proves agent 1 eventually consumes 0 (Friedman was right in the infinite long run), the Yan (2008) result shows that the speed of this decay is determined by the Kullback-Leibler divergence between the two beliefs. If agent 1 is “crazy” (beliefs are very different), grows fast and he vanishes quickly. If agent 1 is “smart but slightly wrong” (beliefs are close), grows very slowly and he survives for a long time.
Conclusion: Limits of Market Selection and Aggregation
The Failure of Friedman’s Selection Hypothesis
Put simply, the Friedman hypothesis (that irrational agents go bankrupt and disappear) holds only in very special, extreme cases. For example, if an agent is “dogmatic” and assigns zero probability to an event that actually occurs, they will be blown out of the water by arbitrage (opponents will bet enormously against them). However, in general, as long as agents have absolute continuity (assigning some positive probability to the truth) and avoid risk-neutral behavior, they disappear very slowly and influence prices for decades.
The Failure of Aggregation (“Wealth Distribution” Problem)
Consequently, aggregation does not hold: we cannot use a representative agent shortcut. Because agents differ in their beliefs, they will hold different portfolios. Over time, wealth shifts toward the agent whose beliefs were closer to the realized data. This means that individual consumption depends not just on aggregate endowments (), but also on the evolution of subjective probabilities determining who was right in the past. Thus, the likelihood ratio tracking belief accuracy becomes a new, necessary state variable. To compute stock prices, one must now track the entire distribution of wealth between optimistic and pessimistic agents, making the model significantly more complex.
Parameter Uncertainty vs. Model Uncertainty
Finally, there is a subtle philosophical inconsistency in standard Bayesian models. Usually, we assume only expectations on stochastic variables (like dividends) are mistaken. However, agents are assumed to perfectly know the pricing functional : this is equivalent to assuming that they know exactly how the economy works, given the parameters. This implies that behind standard Bayesian learning, there is still a strong RE assumption: agents are assumed to have innate knowledge of the structural equations of the economy. A more realistic approach relaxes this, allowing agents to be mistaken about the pricing function itself, learning the relationship between prices and fundamentals from scratch (Internal Rationality).
Disagreement and Asset Pricing
Asset prices incorporate opinions about stocks. Important results show that, if opinions (in particular, priors) were identical and correct, no trade would occur in equilibrium – the previously mentioned no-trade theorems. A whole body of literature incorporates this idea in the form of “agreeing to disagree”. Important results include that mistaken agents may survive forever (Blume and Easley, 2006) or elicits additional volatility in stock prices. In fact, X-CAPM models show how agents interact in incomplete markets, but does not explain stock market volatility well.
Various papers emphasize that different expectations augment the effects of market frictions. In what follows, we will discuss such effects on debt limits. Suppose there are two possible realizations for aggregate dividends, . The budget constraint for agent in period is:
To ensure this maximization problem is well-defined, we must rule out “Ponzi schemes” (where an agent borrows indefinitely without ever repaying). In standard complete market models, this is achieved by the natural Debt limit (or transversality condition), which limits borrowing only to the present value of future income. However, to introduce a market friction, we assume consumers face a tighter, explicit debt limit:
for some finite bound . If this imposed limit is sufficiently large that it never binds, the friction becomes irrelevant, and we recover the standard complete markets allocation (where the agent is only constrained by the true transversality condition). Conversely, if is tight enough to bind, agents become liquidity constrained, preventing perfect risk sharing.
Consider the case where binds. The FOCs are, for each agent and bond:
Suppose that one agent, , is more optimistic, that is . Intuitively, equilibrium is such that and , and vice versa for . That is, agents buy (issue) bonds contingent on their relative more (relatively less) likely scenario. Intuitively, it must be that:
Of course, when the negative values approach , the price of the high contingent bond will likely hold with equality (the constraint is binding). Then,
that is, agent 1 is the marginal agent for the bond, and vice versa for the bond: only the marginal agents’ beliefs matter for pricing their respective bond.
A stock is the same as a portfolio of dividends and price, that is . No arbitrage pricing implies that the price of a stock is:
where:
Disagreement brings uncertainty about the marginal agent pricing the asset each period.
Papers exist along this literature:
- Scheinkman and Xiong (2003) on price bubble through frenzied trading;
- Over-investment: Bolton, Scheinkman and Xiong (2006)
- Crashes: Abreu and Brunnermeier (2003) and Hong and Stein (2003);
- Credit cycles: Geanakoplos (2010).
For a survey, see Xiong’s Bubbles Crises and Heterogeneous Beliefs. A big issue with this literature is that agents agree on the pricing function. They only disagree about future returns to the extent they disagree about probabilities of future . That is, they instance Bayesian-RE. As a consequence, few of those papers explain observations quantitatively, and most find insufficient volatility of stock prices.
Self-referential learning
Self-referential learning involves learning endogenous variables: expectation thus ends up determining equilibrium quantities, but since agents learn from prices, then prices also affect expectation back, in a feedback loop that gives place to non-trivial dynamics. Relating this to the previous example, this can be interpreted as if expectations about prices influence the final bond price, which did not happen in previous cases.
Suppose agents don’t know how prices are formed. To form their expectations, they use some econometric model. Assume that with exogenous and independent of prices.
What are the dynamics of prices if agents learn about how to form ? To obtain closed-form solutions, assume that is a mean-zero random walk. Suppose investors believe prices follow the perceived law of motion (PLM)
and, given such beliefs, knowledge and priors, they learn about mean prices using the Kalman filter (local level model) given . Does converge? It is not obvious, as learning is self-referential. Learning is self-referential if depends on but depends in turn on .
Assume for now they are certain about the arbitrary value of . Put simply, there is no learning and they are stuck at some non-RE . Sticking these expectations in the model we get the actual law of motion (ALM):
which implies that the actual mean of tomorrow’s price is . Put simply, maps perceived to actual expectations; RE is fixed point in this mapping:
While the simple mapping was basically equivalent to what old Keynesian models were doing, the fixed point is basically an incorporation of Lucas’ famed recommendation into a learning framework. Plugging the fixed-point value into the actual law of motion, we get the actual rational expectations price . Standard economics assumes we are already at the fixed point : we assume agents figured it out instantly. Instead, this model studies the dynamics of when we are not at the fixed point. Does the map push agents toward the fixed point (convergence/stability) or push them away (bubbles/instability)?
Suppose now that agents are less stubborn, and have the following PLM:
Given this model and this prior knowledge, the expectation can be derived as the optimal belief through the Kalman filter:
which creates a feedback. When agents believe in this Kalman filter for Bayesian updating, they can update optimally their given their model, which is then used as an input in the price . Expectations of agents influence actual prices. It is not obvious that this procedure converges, but a convergence theorem from engineering could eventually be applied to this case. Note that is basically and OLS. A theorem by Ljung guarantees that if and only if the non-stochastic ordinary differential equation
is stable (converges). Finding stability of this equation is relatively easy. Since , this is a discrete nonstochastic system, and least squares learning works just as small steps towards the true expectation. If, instead, , then these small steps would lead us away from RE. This suggests that not only the rational expectations algorithm, but also the perceived expectations algorithm should contribute to inform expectations robust policy. Moreover, as RE models may exhibit multiple equilibria, these can be used as selection criteria to choose stable rather than unstable RE equilibria (see Woodford).
E-stability
where is OLS estimate of .
Then, if and only if the o.d.e. is stable. That is , there is local convergence if all eigenvalues of are less than 1 in real part.
In the case of the Kalman filter with constant gain:
Basically, is an AR(1), stable for . Williams (2019) shows that, in a general model, constant gain learning behaves like .
What if an algorithm different than OLS is used? For example, . Clearly, must go to infinity to have a chance of convergence; but something more is needed. In fact, substituting out:
with chosen such that . If goes to infinity too quickly, the sum is not absolutely summable and does not converge summing in an infinite sum. In other words, update is not fast enough relative to time, and learning does not occur.
A Learning Model of Real Money Balances
Suppose the price level follows the process:
Then, the perceived law of motions is:
for some forecast error . This can be solved by OLS: . This implies that:
which converges only if .
A Generic Model of Learning
Agents have to forecast a variable given information on . Let vector-valued contain all the variables, including and . Assume that the model is such that equilibrium depends on agents’ forecast . Agents’ perceived law of motion is:
so that they set
for some not yet determined. Assume the model is such that, in this case, the true evolution of the series is:
and in particular that
In this case, agents are correct about what variables drive movements in . If agents think that variables evolve with a parameter estimate so that their expectations are given by ^aa25f4, then the true conditional expectation is given by:
Therefore, the mapping maps perceived (coefficients’) expectations into actual expectations.
Special cases of this algorithm include:
- Rational expectations, which amounts to .
- Least Squares Learning, which uses OLS to estimate Standard convergences theorems in econometrics, however, do not apply: in standard econometrics, does not (and should not) depend on . A new theorem must be provided. Such theorem is presented in Ljung (1977) and Marcet and Sargent (1989a,b).
General Convergence for Stochastic Approximations
Define and the ordinary differential equation . Denote a stationary point of the o.d.e., .
If:
- is given by
- observed series satisfying ^308db5 with eigenvalues less than in real part
- is a given series of numbers and
- given functions
- square-summability:
- other technical assumptions
Then:
- Claim 1: can only converge with positive probability to a stationary point .
- Claim 2: stable at
Intuitively, the o.d.e. approach can be represented as:
where the left-hand side is “close” to , while the right-hand side is “close” to .
OLS is a Case of ^242a00
Suppose that . Note that:
Moreover, it holds that
which can be plugged into the first equation to obtain:
This shows that OLS is a special case of bullet-point one in ^242a00 when we take the following:
To build the o.d.e. that corresponds to this case, take the expectation of :
Note that the second moment is a function of , since . This gives the associated o.d.e.:
A stationary point of this o.d.e. is at and . So, cancels out and the only relevant condition for stability is E-stability, that is .
This idea can be extended to:
- multivariate
- private information (Marcet and Sargent, 1989b)
- non-linear models (Kuan and White, 1994; Chen and White, 1998)
- Other learning schemes
- Some non-stationary models
As Sargent once put it, there is a general idea that deviating from RE hurls analysts into the “wilderness of irrationality”. The main arguments usually put forward against learning are the following:
- Lack of discipline. Any kind of expectations could be validly assumed, generating wilderness.
- Unfalsifiability. Liberalizing learning and irrational expectations creates ad hoc models that cannot fail. This resonates with the large old Keynesian models of the 70s.
- Irrationality. While learning about fundamental shocks is considered acceptable, most economists would reject that agents view prices as deviating from fundamentals.
These good concerns can easily find counterarguments in support of learning.
- Expectations can be disciplined through empirical validation, such as looking at surveys and testing if the PLM are compatible with observed data on expectations.
- If unfalsifiability is imputed to overparametrization, learning models are no more overparametrized than many RE models. In particular, it is possible to design learning models that are just as parsimonious or even more parsimonious in terms of parameters.
- If agents learn about prices, expectations don’t need to be “fairly good”. The only required criterion may be “internal rationality”.
Internal Rationality
This section incorporates summaries of Adam and Marcet (2011), Adam et al. (2016, alias AMN), and Adam et al. (2017, alias AMB).
Consider a Lucas’ asset pricing model for a consumer problem:
The only difference in this model from Lucas’ original lies in the generality of expectations: exogenous variables are perceived according to some distribution of , where is omitted for simplicity. This means consumers choose:
that is, they choose contingent plans for each possible history of external variables. This separates the issue of optimality from the RE paradigm: agents behave optimally, given their perceived probability distributions. In this sense, the deviation from orthodoxy is only small, since individual optimality is not rebutted but conditioned on some specification for expectations. Compared to contemporary RE models, this choice forces the analyst to be explicit about assumptions about the model of prices employed by agents. The learning algorithm is then derived from optimal behavior given , a process that can be interpreted as microfoundations for adaptive learning. Put simply, the optimal algorithm must be derived from assuming a model of pricing. Then, this model can be tested in the data, with very encouraging results.
Once is part of the model assumptions, a rule must be specified accordingly. In AMN and AMB, the simplest behavioral assumption is that agents have correct beliefs about dividends and income; but a mistaken view about stock price growth. In particular:
The agent’s expected growth is derived from this belief with a constant-gain Kalman filter.
As we will verify, this specification for expectations is strengthened by the fact that it elicits these desirable properties:
- Closeness to RE
- Closeness to data
- Closeness to the model (the perceived law of motion is relatively close to the actual law of motion)
- Compatibility with survey expectations
In particular:
- If , agents’ belief are close to RE.
- is MA(1), and this could be tested by the agents making the model falsifiable. In fact, letting and can be tested by GMM through suitable instruments and noting that . The results are reported in the following table:
| Regressors (4 lags) | |
|---|---|
| 6.69 | |
| 6.66 | |
| 6.97 | |
| 6.33 | |
| 4.68 |
which are all significant at the 5% critical value (9.48).
In this model, the authors follow standard practice in RE and Bayesian-RE literature, and assume that agents know the pricing function at all . The key consequence of that unrealistic assumption is that the joint distribution of all possible combinations of prices () and data () that could ever occur, involves a singularity, meaning the relationship between the variables is perfect, fixed, and deterministic from the very start: . This allows to rewrite the choice problem as:
To continue, derive the optimality conditions for the model. Some authors argued that holding beliefs about prices is irrational, and the FOC would be something like . However, it is false that agents’ optimality conditions contradict price beliefs. The only reason you would think there’s a contradiction is if you use the misspecified FOC, where you illogically assume agents ignore prices in their decisions3. If you use the correct FOC, where agents do use price information, then their beliefs and their decisions are perfectly consistent. In fact, the true FOC is:
If agents deviate from RE, they see themself as choosing something different, depending on the price, and according to their belief. The current market clearing prices must be consistent with expectations about price dynamics, as the decision is optimal given their belief. Agents do not see that in equilibrium consumption is identical to the dividends; they only project themselves buying and selling depending on the prices at any period. In other terms: The stochastic discount factor does not incorporate realized consumption, but rather expected consumption.
This model is also capable not only of rejecting RE, but also of accounting for Figure 1 in AMB. In fact, this model can also be put through a formal test by Simulated Method of Moments4. The results of the SMM simulation are presented in the following Table from AMN.
| US Data Moment | Estimated Moment | t-statistic | |
|---|---|---|---|
| Quarterly mean stock return, | 2.25 | 1.49 | 2.06 |
| Quarterly mean bond return, | 0.15 | 0.49 | -1.78 |
| Mean PD ratio, | 123.91 | 119.05 | 0.23 |
| Standard derivative of stock returns, | 11.44 | 11.60 | -0.06 |
As the values and t-statistics suggest, empirical variance is successfully matched (recall how difficult this matching used to be with previous models) in a statistically robust way. Moreover, surveys seem highly correlated in the data with the estimated moment. This simple specification solves most of the problem that emerged so far. The fit of the model can improve dramatically with very simple additions, and further extensions can be implied.
An easy way to solve is model is by assuming the following optimality condition:
where the third-to-fourth line is justified assuming that only a limited portion of their wealth is in stocks relative to dividends (that is, is very small). The denominator contains the agent’s belief about price growth, . As agents become more optimistic (expecting higher growth), the denominator shrinks (). As the denominator gets close to zero, shoots up to infinity. This mechanism explains the bubbles and high volatility ( ratio explosions) observed in the data.
Then, for the risk adjusted prices , the solution is:
that is, the current dividends times their known growth rates. In some ways then, this resembles a bubble: if, for any reasons, is high (read, agents are optimistic), then current prices go up, leading to higher and ultimately blowing up again, in a positive feedback. This is a bubble, although not a rational bubble. For example, if there were an upper bound for , then prices would not be able to grow longer and become constant; then, this would bring revisions of in the negative territory (verify with Kalman filter formula), implying that a bound would force e a bubble to revert at some point. Of course, this implication from to prices and not the opposite is due to self-reference, and the opposite relationship would be implied by a Bayesian-RE learning model.
Extensions
Other papers from this research program include:
- Adam and Marcet. Internal Rationality and Asset Prices, JET
- Adam, Kuang and Marcet. House Price Booms and the Current Account. NBER Macroeconomics Annual.
- Adam, Beutel, Merkel and Marcet. Can a Financial Transaction Tax Prevent Stock Price Booms?. JME
- A few others by Klaus Adam and his coauthors
How does this instances in practice? A serious example might be the “Fed Put”: Bernanke claimed that the Fed would not intervene during a bubble burst, and his 2006 position was fairly standard among economists and policy makers. Yet, in 2008 Bernanke organized one of the largest stock purchases by the American government that ever occurred in history. So, one may claim he might have not believed what he said in 2006 at any point. Current research about the so-called “Fed Put” demonstrates central banks systematically intervene at stock market busts, basically insuring put options. This is a crucial phenomenon to understand if and why central banks should intervene in the stock market, and provide insurance to investors with the potential to affect income and wealth distributions and distort incentives or elicit moral hazard.
This literature is also connected to the research on collateral constraints and the financial frictions model by Kiyotaki and Moore. A specification of this learning design, as an extension of the previous model, was introduced by Winkler (2020), who imposes that firms face a borrowing limit equal to or their market value. This links investment to stock prices. Under RE expectations, such a relationship has limited effects. However, under learning, stock price boom creates an increase in investment, fueling the business cycle. This is confirmed in the data, here investment responds positively to stock price shocks, and the model provides a straightforward argument to avoid stock price bubbles through central bank interventions.
An Application: Learning about Bond Prices
Many studies focus on stock price volatility, but research on bond price volatility is relatively underdeveloped. As previously argued, we may want to learn about stock prices using learning models with internal rationality. On a similar not, how much can be learnt about bond yields using models of internally rational learning?
This model applies the previous ideas to bond yields, using nominal yields in monthly US data for almost 40 years combined with surveys (Reuters’ Blue Chip FF), focusing on one-year forecasting horizons.
Evidence from the Yield Structure
A main target of this model is the flat term structure of yield volatilities, which is hard to reconcile with RE and (reasonable) serial correlation of expected inflation:
| 1y | 2y | 3y | 5y | 7y | 10y | |
|---|---|---|---|---|---|---|
| 388.83 | 417.23 | 441.39 | 481.19 | 510.89 | 541.69 | |
| 289.15 | 294.34 | 291.41 | 281.62 | 272.50 | 258.74 | |
| .89 | .90 | .91 | .93 | .93 | .93 |
In actual practice, the expectation hypothesis does not hold. Consider the model:
If the expectations hypothesis were true, then . This equation is a test of how the current yield curve predicts future yield movements. Assuming is the yield of the -year bond at time , when it has years left to maturity, the model is testing the core implication of the expectation hypothesis as follows: The term on the right, , is the normalized yield spread, while the term on the left, , is the actual change in the long-term bond’s yield over the next period. Since the expected change in the long-term yield must be exactly equal to the normalized yield spread, that is, , the regression tests if the actual, realized change (the left side) moves one-for-one with the theoretically expected change (the right side). This fails in empirical practice:
| 2y | 3y | 5y | 7y | 10y | |
|---|---|---|---|---|---|
| -0.31 | -0.50 | -0.99 | -1.28 | -1.67 | |
| t-stat | -0.43 | -0.60 | -1.21 | -1.56 | -2.16 |
An alternative, “modern” version of this test focuses on the forecasts:
where the expectation hypothesis would predict , and the LHS denote the marginal profits from long bonds. This test also fails in practice:
| 2y | 3y | 6y | 8y | 11y | |
|---|---|---|---|---|---|
| 0.61 | 2.54 | 10.69 | 15.87 | 24.17 | |
| t-stat | 0.52 | 1.14 | 2.40 | 2.87 | 3.54 |
| 0.32 |
(Note that surveys have 1t, 2y, 5y, 7y, and 10y horizons, so can be used to predict year-ahead values for the following year.) Moreover, the volatility of excess returns, measured as , seems to increase in the horizon:
| maturity | 2y | 3y | 5y | 7y | 10y |
|---|---|---|---|---|---|
| 136.60 | 256.20 | 455.74 | 636.45 | 880.10 |
Why does excessive volatility of long-term yields suggest a failure of RE? Note that today’s price of a bond can we rewritten as:
where refers to the risk-neutral distribution. Taking a log-linear approximation:
Once again, two averages are being computed: an average over the horizons , and an average in probabilistic terms (the expectations). By this, we would reasonably expect that : the opposite of what happens in the data.
Moreover, excess returns can also be expressed as:
where . This highlights that can be interpreted as a change in expectations, and should be small under RE.
RE can be further tested through survey data. In AMB, the following test is proposed. Let denote survey expectations and take an equation similar to the test for the expectations hypothesis:
Under rational expectations, it should hold that , for the values of the excess returns found above. The regression contradicts this prediction:
| 2y | 3y | 6y | 8y | 11y | |
|---|---|---|---|---|---|
| 0.61 | 2.54 | 10.69 | 15.87 | 24.17 | |
| 0.16 | 0.80 | 2.50 | 1.27 | 3.69 | |
| t-stat for | 0.37 | 0.76 | 1.75 | 2.47 | 2.70 |
In outline, it emerges that , and both are larger for longer horizons. That is, survey underestimate the role of the slope in predicting the excess returns. RE are rejected by the -test – the longer the maturity, the stronger the rejection.
What if the simple slope isn’t the right variable? What if investors use a more complex measure of the slope? Does the RE hypothesis still fail? To answer this, test two new “alternative regressors” that also capture the slope of the yield curve:
- The Principal Component, . This is a purely statistical measure used to statistically extract the slope information from the entire set of bond yields.
- The Model’s Slope Factor . This is an economic measure derived by the own model-based estimate of an “underlying slope” that investors see.
The core idea is to see if the main conclusion (that RE fails) holds true even when using these more sophisticated slope measures. This test also rejects RE:
| regressor | 2y | 3y | 6y | 8y | 11y | |
|---|---|---|---|---|---|---|
| 0.06 | 0.13 | 0.43 | 0.61 | 0.89 | ||
| 0.02 | 0.05 | 0.14 | 0.13 | 0.19 | ||
| t-stat | 0.85 | 1.22 | 1.98 | 2.57 | 2.87 | |
| 1.04 | 2.16 | 9.14 | 13.90 | 22.67 | ||
| 0.41 | 0.57 | 0.28 | -2.28 | -2.86 | ||
| t-stat | 0.77 | 0.95 | 2.12 | 2.79 | 3.08 | |
| p-value | 0.70 | 0.59 | 0.09 | 0.01 | 0.00 |
Conclusions
What often policymakers to is to evaluate the stability of a policy based on the underlying objective probabilities. In contrast, Molnard and Santoro (2014) evaluate optimal monetary policy in a New Keynesian model when agents are learning. In particular, agents update their view based on output, with the PLM and updating the gains . Expectations are a “stock” that policymakers build and would like to avoid shocking or surprising (a forward guidance term in the update could be included, such as for some promised output of inflation). Other papers on learning in NK models is provided by Eusepi and Preston (for instance, the review The Science of Monetary Policy: An Imperfect Knowledge Perspective).
Optimal Policy under Rational Expectations
Optimal Labor Taxation (Lucas and Stokey, 1982)
Is it possible to improve a dynamic competitive equilibrium with optimal fiscal policy? The classical reference for this class is the model by Lucas and Stokey (1982, JME). In particular, they take the simplest dynamic economy possible: a labor economy where government only sets taxes, and check what’s the best path for taxes.
Complete markets
Assume homogeneous agents with utility functions:
(where is the disutility of labor, so ). A firm produces output with linear technology , and the ^8ffdc9 takes prices as given and complete markets. Suppose a government must satisfy an exogenous stochastic spending sequence with some support at every time. Consider proportional taxes on labor income, with tax revenue . Moreover, the Ramsey planner has access to full contingent claims. Of course, these are contingent on the only stochastic quantity, . The period 0 implementability constraint is derived from the agent’s optimization (their FOCs and budget constraint). The household’s (flow) constraint is:
and its time-0 counterpart can be obtained by setting and forward iteration:
Then, note that the FOC from ^3bfb12 are:
which can be, as usual, chained back to time 0:
Finally, plugging in the expression from obtained in ^f2dd2c, the resulting time-0 budget intertemporal budget constraint is:
meaning that the present value of the agent’s net consumption must equal their initial bond holdings. In this setup, the optimal policy problem is to find the stream of taxes such that:
A Ramsey policy is distinguished from a time-consistent policy or partial information policy, and it is nowadays used to denote a full-commitment full-information policy.
Ramsey Policy
A full-commitment, full-information policy.
Note that is both time-dependent and dependent5. Full-commitment ex ante implies the government cannot re-optimize later; it must follow the pre-committed state-contingent plan, even if a peculiar shock sequence occurs. The problem must be solved subject to the competitive equilibrium, that is the Ramsey planner understands that their chosen tax affects the economy through the competitive equilibrium.
To solve the model, we start from market clearing. By market clearing and the linear technology, . The bond market also needs to clear, implying . By firm optimization and the linear technology, it also holds that . Thus, when the consumer maximizes their utility subject to the budget constraint, their intratemporal6 first-order condition (which involves a non-zero Lagrange multiplier on the budget constraint) gives the usual condition:
that is, the marginal rate of substitution must be equal to the disposable wage. Since wage is unity, it must also be that . Also, note that optimal taxes can be found without solving for the bonds, which also allows to get rid of another equilibrium condition. In equilibrium, . Note that . Substituting back in the agent’s budget constraint, we summarize the entire set of constraints in a unique equation:
which can be rewritten equivalently as:
by the previous BC satisfied and Walras’ law, also the government budget constraint is satisfied. The entire problem can be recasted as:
Note the constraint has been made explicit by substituting . By setting up a Lagrangian for the implementability constraint:
Note that is a single, time-invariant Lagrange multiplier for the single present-value constraint. Therefore, the first-order condition (FOC) with respect to (for any and state ) follows from this Lagrangian. This FOC can be represented “conceptually” by a pseudo-utility function7, where the constants figuring are omitted:
where . We use (or in the paper) to denote the multiplier .
If we wanted to solve for bonds, we should simply remember that period 0 budget constraints must also hold for every period in the future; therefore, the government bonds held by the agents . The multiplier can be found such that, choosing the according consumption, the previous constraint for period holds. This is usually solved by numerically finding the that satisfies the constraint.
This equation is the optimal policy under the Ramsey assumption: the policymaker is benevolent, there is full commitment. The FOC for is structurally different from the FOC for . This is because also appears in the pricing kernel for all . By changing , the government can manipulate the real value of all future payments, including the initial debt . This creates an incentive (similar to a “capital levy”) to distort the tax rate. This is why is generally different from future tax rates. Note that, with risk neutrality, the second derivative would be zero and this condition would always be satisfied. In the terms from the following paragraphs, it implies the interest rate is neutral, and the government can play no tricks to affect the agents’ consumption.
Government cares about taxation due to the MRS. In the first optimum, given linear technology, the technological marginal rate of transformation would be 1: the first best would not be implementable, as it would violate the competitive equilibrium through the budget constraint. In fact, 0 tax in equilibrium implies that disappears from the equation, probably violating the constraint. The first-best (0 tax) violates if is not equal to the present value of government spending. If the government starts with net assets that are exactly equal to the PV of its future spending, the first-best would be achievable.
Also note that8 which implies that the government can engineer levels of consumption to favor itself, for example decrease t consumption relative to 0 consumption so that declines together with . Typically, taxes at period 0 are a bit lower and then they jump to a constant rate. This difference between and is what would introduce time inconsistency, a point brought up by Kydland and Prescott (1977). The central finding of Lucas and Stokey for the barter economy is the opposite: the optimal Ramsey policy can be made time-consistent. This is achieved by letting the government issue a rich set of state-contingent bonds that perfectly structure the next government’s incentives (i.e., its initial debt) to align with the original plan.
The generic outcome of this model is indeed summarized in the . In fact, the variance is low relative to the variance of spending: after the first jump, optimal taxes are fairly constant, although they depend on . This is what people call tax smoothing, a very prevalent phenomenon in the data. This implies that (the deficit/surplus) is usually very high. The opposite would happen with balanced budget, which would however be suboptimal. This is the important result of this model.
The idea that wealth equals discounted future deficits holds not only at the beginning, but throughout the model. What is the wealth of a consumer at period ? At each period, a market for one-period bonds exists, where is all the realizations that can happen for . This pays one unit if and 0 otherwise. Then, wealth is whatever the consumer holds of , which is the government debt issued (positive values denote government deficits). In equilibrium, for all . At the same time, we saw that . In Exercise 3, we are asked to find and , using as a sufficient statistic. This also implies, however, that itself, and also the same function at all periods.
Incomplete markets
Suppose markets are incomplete and the government only issues risk-free one period bonds. The budget constraint for the government and households with incomplete markets becomes:
where market clearing requires zero net supply of bonds, .
What is the optimal policy with incomplete markets? First, find the CE relations. The sequence of equations becomes:
So, the Ramsey problem becomes:
subject to CE.
The budget constraints will now no longer be squeezable into a single time-0 implementability constraint. This is because the asset price and thus the value of debt depends on the state at time , but the debt issued at must be risk-free, i.e., its value is not contingent on the state.
Moreover, consider the government’s budget solved for :
If the primary deficit () did not respond to the level of inherited debt , the debt dynamics could be explosive and violate the Ponzi condition. For example, for high debt or high , taxes must be increased to generate a surplus. In this sense, the dependence of the surplus on the debt is crucial. This implies that, with incomplete markets, the statements and are no longer true. The allocations and must also depend on the level of outstanding debt, .
In outline, with incomplete markets it is never possible to get rid of bonds as a tracking measure for each period. The constraint of the Ramsey problem always includes . In the paper by Aiyagari, Marcet, Sargent and Seppälä (2002), they emphasize that a standard Bellman equation cannot be applied because the policy at is not a time-invariant function of the “natural” state variables (). This is due to the complex, forward-looking nature of the implementability constraints. However, Aiyagari et al. (2002) also show that the problem can be made recursive by adding the cumulative Lagrange multiplier as a state variable. The resulting optimal policy is still a Ramsey plan (assuming full commitment) and is time-inconsistent if that commitment is not assumed. The authors explicitly assume commitment to the Ramsey plan to focus on the effect of incomplete markets.
Let’s maintain a two-agent setup and rational expectations. The two agents with same utility functions but different endowments. Then, the CE with complete markets would be the Pareto-optimal allocation given by the Negishi problem:
with FOCs:
Intuitively, the two agents can share idiosyncratic risk: in any situation, the Pareto-optimal allocation is that . Whenever an agent consumes more than the other, that must be because initially they had more wealth (captured by the Negishi weight ), and the shocks cannot alter this situation as agents are fully risk-sharing.
Suppose that is an AR(1). Any luck for an agent will carry on to future periods. In such situation, nothing changes: the permanent fluctuations are also perfectly shared, regardless of the persistence of the shock.
The previous problem, although not recursive, can be made recursive through a trick analogous to the one outlined by Aiyagari et al. (2002) (who apply it to the Ramsey problem). Instead of an outside option, let’s denote a function . Now, in rewriting the Lagrangian, we include a different multiplier for each period and agent on their participation constraint.
Taking the FOC:
This includes complete markets as a special case: when the outside option is infinite-valued, it’s never binding (that is, autarky is very bad): constraints are slack, , and thus their sum is 0, taking us back to the previous solution. Thus, it is clear by the definition of the lambdas that .
This solution can be extended to the Lucas and Stokey model.
Aiyagari et al. (2002) apply a similar logic. They formulate a recursive Lagrangian where the state variables are the exogenous shock , the endogenous debt level , and the cumulative multiplier . This is the co-state variable that evolves based on the multipliers for the new implementability constraints that arise from incomplete markets.
Their Lagrangian (Eq. 11 in the paper) is:
conditional on assuming . Thus, we can conclude that . Let us break down this result for consumption levels and bonds issuance.
A Detour: Recursive Contracts
The Lagrangian is fully recursive if we include the costate variables, and the optimal consumption levels are an invariant function of the full state vector:
with the inclusion of the optimal costates and a positivity constraint on the Lagrange multipliers . These models, where optimal choices interact with an outside option through the multipliers, are sometimes referred to as models of defaults. However, at least in this case, the constraint is enforced in equilibrium, and default is an off-equilibrium path (the optimal contract is for people not to default). Moreover, note that Lagrangians are maximized with respect to the choice variables, but minimized with respect to the multipliers, which means we are looking for saddle points. Finding the fixed point on a grid where maximization and minimization are simultaneously required means that the value function maximization is not as straightforward as before. Although few assumptions are sufficient to ensure existence of the saddle point, it is theoretically difficult to prove that the of the Bellman equation is also the solution to the maximization problem. Therefore, analysts normally don’t solve value functions for these models, but find the specific FOCs for this recursive formulation.
The FOCs are:
Consider the last FOC. This involves individual-specific inequality constraints. The expectations at time of future consumptions can always be written as a function of the state variables at time , . A discussion on the way to find this function is omitted. Once a candidate is found, the expectation can be computed for the two variables, and combined with a consumption level to check whether the condition binds or not. Consider the familiar two-agent case, which involves two constraints.
- If both are slack, then both . Therefore, the first two FOCs give a system with two equations and two unknowns, and the consumption levels can be found. Then, plugging in the found consumption in the third FOC, the participation constraint can be checked: if these are indeed satisfied as strict inequality, then this is effectively the solution.
- Alternative, suppose that the participation constraint of agent 1 binds, but does not for agent 2. For agent 1, the equality is strict: the third condition is an identity and can be used to solve for current consumption level of agent 1. Then, this value can be plugged into the first FOC to find consumption also for the other agent.
Note that it can’t be that both constraint bind: this would mean that the solution does not exist (they can’t both be leaving resources, the point must be interior)9
The previous paragraph focused on the participation constraint. The reasoning is, however, also valid for the Aiyagari et al. (2002) Lagrangian. In fact, it holds that
The FOCs are as follows:
In the Lucas and Stokey case, the first FOC was similar but displayed a constant multiplier, due to the period-0 budget constraint being the only constraint. Thus, this FOC is analogous to Lucas and Stokey, but features a time variant multiplier: under incomplete markets, the history of shock matters as it is not possible to insure completely. Thus, period by period, the Lagrange multiplier of the budget constraint changes, and it is needed to keep track of that in addition to the terms that were already tracked. To solve for the system, parametrize the expectations and follow steps similar as before, using the FOC directly to solve for the optimal solution10.
In a recent paper by Faraglia, Marcet, Oikonomou, and Scott (2019), the authors develop a model in the previous spirit and explore how a government should optimally choose the maturity of the debt to issue. The model matches some stylized facts about bond issuance and government debt. This can be combined with the literature on sovereign debt crises to explore how the optimization changes when the government can effectively default and has a default outside option11.
Optimal Capital Taxation
In real-world economies, capital taxes are exacted on several sources: dividends, gains, corporate, and more. The issue of optimal taxation is particularly important in capitalistic economies, and in recent years capital taxes have been steadily declining. This section of the course focuses on famed papers by Chamley (1986) and Judd (1985), as revisited in the 1998 handbook chapter by Chari and Kehoe12.
Firms produce with constant returns to scale, . Consumers have same utility as in Lucas and Stokey’s model; can save and dissave; however, they now face no uncertainty. However, consumers now own the capital stock , and receive capital income . Then, consumer pay capital taxes . The consumer problem is thus:
Firm statically optimize profits, where rental rates and wages are the marginal product of the corresponding factor. The government has a symmetric budget constraint, .
The Ramsey full commitment optimal policy would be framed as:
where full commitment is captured by the fact that the full series is chosen at time 0.
Let us simplify the CE condition and solve the model by substitution. By Walras’ law, the government budget constraint is already satisfied by the consumer’s budget constraint. The rental rate and wages can be directly plugged into the equation as equilibrium objects. Last, instead of , the law of motion of capital can be plugged in, as . As a result, the FOC of the consumption problem is the usual identity of the MRS, . Similarly, the FOC of capital is the MRS for capital: . Finally, the condition with respect to bonds is . Summarizing:
By combining these conditions and substituting:
From here, it is possible to get a discounted budget constraint. Note that the items in brackets embody total wealth without working, at periods and respectively. By substituting forward, one can obtained that:
Note that no placeholder for investment appears in the equation. This comes from the fact that , total wealth in period 0, must be just as if the consumer foresees all the capital stock in the future, and instead purchases government bonds that yield a lot of interest. Since there is no uncertainty, bonds and capital must yield the same returns. Therefore, it is the same to write this functions with investment or forgoing capital stock altogether. In practice, capital will also be present in equilibrium; this condition simply states that the consumption decision is as if investment did not exist.
Subsequently, we argue that the only constraint that the Bellman should keep track of (on top of feasibility) is the wealth constraint. In fact, for any such level of wealth, it is possible to find a capital tax such that the capital FOC holds; similar reasoning can be applied for labor. Last, the government bonds can be traced back from the budget constraint once consumption is pinned down. Therefore, the only necessary implementability constraint is exactly ^f243b0. This allows to rewrite the Bellman problem as:
In some sense, only the matter and affect investment. In contrast, does not affect the consumers’ FOC. Yet, it appears as an index of maximization. Time-0 taxes can be thought of a capital “expropriation” rate, for the initial given stock of capital. It is easy to show that, without further refinements, the optimal solution for this model is simply to impose an infinite capital tax at period 0, and then let free capital exchange and collect 0 taxes. To make the model more interesting, then, it is often assumed that , so that is not a choice:
The key result remains valid: starting existing capital should be taxed as much as possible, as this choice has no consequence and does not distort investment incentives, thus it provides revenue without depressing output. The reason to tax early in this model is intrinsic. Of course, this simplified model abstracts completely from “real world reputation”, where people may reasonably suspect that capital taxes will still be high if a dramatic is imposed.
It is more interesting to explore the optimal taxes through the Lagrangian multiplier.
The FOCs are similar to Lucas and Stockey:
From this, we observe the Chamley result stating that, as , the two quantities will cancel, and . What is the corresponding tax? From the consumer problem, we have that must hold. In steady state, this simplifies to which implies that taxes should be 0 in the long run. This can be visualized by looking at the consumer’s Euler:
In the Steady State, consumption is constant (). We can cancel the marginal utilities:
This defines the private return on capital required by savers. Set the two equations equal to each other:
Assuming the marginal product of capital , the only solution is:
Chamley Result
In the long run, .
Even with heterogeneous agents, this result is robust. In fact, what happens is that the planner’s weight for a Pareto optimal allocation will be imposed, but everything else will basically be solved in the same manner, with an implementability constraint per agent, which means two different , which however does not enter the optimal tax equation.
What is the intuition behind this result? In the original Ramsey model, optimal taxation requires that an elastic good should not be taxed, because a small variation in taxes induces a huge movement in the market allocations. Inelastic good imply smaller distortions in the equilibrium; a completely inelastic good would be the ideal good to tax. Capital supply in the first period is a totally inelastic good: the supply is given. This is why we obtained the original result that, for unlimited , we should impose infinite taxes. Long run capital, instead, is totally elastic. In fact, only one price exists: , which means . The optimal policy in this scenario is that capital taxes are very high at the beginning — as much as the upper bound allows — but will then go to zero. In contrast, labor taxes will settle to a positive constant. What is the source of time inconsistency? The source of such inconsistency is that, after period 0, it would always be that at some time it is to treat as an initial, inelastic capital stock.
In this section, we focus on a paper by Straub and Werning, that contends the statement that the is flawed. The multipliers in the optimal allocation could tend to infinity, even in an infinite-growth economy. In fact, Lagrange multiplier do not admit constraints, and there are cases where the optimal allocation requires infinite multipliers. Then, has some constant , thus either exploding or shrinking.
Optimal Capital and Labor Taxation
In a paper by Greulich, Marcet and Laczó, they have a two-agent model and tax also labor. In particular, agents have different productivities as . Defining output as , the competitive wage is , where .
The maximization is similar as before, and once again we have three constraints that simplify to two by Walras’ law. the FOCs of the problem become:
The government cannot break the intertemporal identity enforced by the individual optimality conditions. The ratio of consumption will thus be constant. This means that ratio of consumption stays in place for all histories. However, we can set this to an arbitrary level at period 0: the commitment about the entire path of taxes decided at period 0 permanently settles the marginal utility ratio on a specific level. This level is chosen so as to maximize the planner policy:
Then, the previous relation would be , and thus the examples by Straub and Werning must have been mistaken, and included paths where consumption went to 0. This result recovers the Chamley result and is robust to homogeneity (i.e., heterogeneity is not required to obtain this result).
Additionally, a Pareto-optimal frontier can be drawn. In particular, the total utility of the two agents can be plotted by first identifying the status quo (i.e., the current level of taxes), and the status quo utility that would follow the current policy. Then, varying , trace the Pareto-optimal frontier. The status quo can be beaten.
\begin{document}
\begin{tikzpicture}[scale=2]
% Axes
\draw[->] (0,0) -- (1.8,0) node[right] {$u_1$};
\draw[->] (0,0) -- (0,1.8) node[above] {$u_2$};
% Quarter circle with radius 1.5
\draw[thick] (1.5,0) arc (0:90:1.5);
% Labels for alpha at the axes intercepts
\node[left] at (0,1.5) {$\alpha=0$};
\node[below] at (1.5,0) {$\alpha=1$};
% Status Quo point at (1,1)
\coordinate (SQ) at (1,1);
\fill (SQ) circle (1pt) node[above right] {\textit{status quo}};
% Dashed projections to axes
\draw[dashed] (1,0) -- (SQ) -- (0,1);
% Optional: Add ticks on axes for the projection
\draw (1,1pt) -- (1,-1pt);
\draw (1pt,1) -- (-1pt,1);
\end{tikzpicture}
\end{document}In most papers on optimal policy, , and are referred to as “Benthamite” models. However, this is a weird result: in microeconomic theory, utilities are not presented as a cardinal concept, and adding up utility functions has no meaning. In fact, a midpoint is places in random location of this curve (depending on the specifications, it could be in points very favorable to agent 1 or vice versa). Pareto-improvements require the right parameter, and this is usually not equal weighting.
Even more so, it can be shown that the continuation policy remains Pareto-optimal, for some weights and suitably adjusted multipliers : there is also a triplet that satisfies the optimality and thus the policy is now time-consistent. Of course, however, it must be that . If agents are sufficiently similar, it might be that : in that case, time inconsistency arises. However, for sufficient heterogeneity, the required , and the continuation remains Pareto-optimal.
Policy Concepts
Time-Consistent Policy
A time-consistent policy or a policy under discretion or policy under no commitment or symmetric Markov perfect policy is a policy such that the government:
- chooses
- takes as given
- takes as given , so that future governments are also assumed to take future inherited debt stocks as given
- it maximizes utility
- in equilibrium, they take the same policy function13
The reference paper for this kind of policy is Klein, Krusell, Rios-Rull (REStud, 2007-8). In New Keynesian models, the policy under discretion is even easier, as there is no state variable, so the expectation about the future is basically just a number. Note that no theorem similar to Blackwell ensures that this is a contraction and value function iteration converges: this is not the Bellman equation, as does not represent the optimum. The optimum is attained through full commitment: this is simply a specific game-theoretical solution concept.
Some in-between models also exist. For instance, Debortoli and Nunes propose loose commitment (2010-1). Suppose a government commits with probability , which applies iteratively at every period. With probability , commitment is lost and a new government will propose a new policy, also under loose commitment. In the Lucas and Stokey model, the government would choose a whole sequence of bonds and taxes as follows:
in case is an exogenous number. This means that the government has a different, more aggressive discounting than the people. The outside option can also be endogenized, or be put in place for a limited number of periods.
Models of Democracy
This model introduces voting into the picture. Loose commitment has a flavor of democracy, but the regime shift is stochastic, such as in Alesina and Tabellini. If the probability of success in election is endogenize, it ends up affecting the planner’s objective function.
Consider the model with risk sharing and consider random endowments with lump sum taxes. Consider two parties, A and B, such that , with probability in power and . The utility of agent if party is in power can be written as:
Furthermore, we assume parties are fully committed to their programs, that is . The objective function changes accordingly:
where the are endogenous objects that will be specified soon. In that problem, individual utility can be updated as:
where . These model often introduce probabilistic voting: in this dynamic setup, this means that there is a continuum of agents indexed by , and agent of type values the policies as , meaning that party might offer a better deal but idiosyncratic shocks affect their vote (such as exogenous concerns or deviation noise), and time-specific “popularity” facts such as “scandals” affect the continuation values. The proportion of voters for is defined as . This can be translated into a probability of winning the elections, which occurs if the previous proportion is greater than .5. The, , that is the probability of the popularity is greater than what is needed to win. This can be finally incorporated as an additional constraint for the planner’s maximization problem.
Q&A
As for inducing the best expectations, Marcet seems to suggest we should basically design an information device which “implements a mechanism” such that we give agents’ the information relevant to induce them correct expectations.
Lucas’ critique al belated policy. Proposed solution: use tilde expectations for current regime and assume RE after regime switching, to follow Lucas’ recipe at least after regime switching. This makes the paper easier, but it is probably not reasonable in actual practice. Alternative: acknowledge we don’t know what expectations will be, and make a guess as an analyst.
Footnotes
-
Many authors from all areas of economics introduced forms of “keeping up with the Joneses” behaviors. It is clear what these authors are trying to capture: Some of our consumption-saving behaviors are driven by relative consumption concerns. However, imposing relative consumption into utility function leads to unpleasant results, such as the “rat race”. Not only that: It is also unrealistic. No agent would ever commit to or identify with a utility function including other peoples consumption (if you’re not convinced, imagine a survey where you asked if you’d like to make everyone poorer by 50% and yourself poorer by 1%: how would you reply?). Instead, it is way more promising to include relative income concerns into the policy function, as a source of non-stochastic error derived from a behavioral bias. ↩
-
This technique is called the Negishi algorithm. It simplifies asset pricing by solving for quantities (Consumption) first using a Planner, and finding prices (Asset Prices) second using Marginal Utilities. This is only possible because financial assets net to zero in the aggregate constraint. ↩
-
I do not see how this mistaken FOC could be derived for this model. It seems like a non sequitur, or better, a straw-man argument developed on purpose by opposing analysts. ↩
-
The SMM estimates a times series generated by parameters, that is . The model tests the following identity:
This is a special case of GMM and can be solved through the same estimator . ↩
-
In principle, government debt holdings are a function of the entire history of shocks . However, this dependence can be reduced to a one-period current dependence from , in analogous way as we transformed ^e8b054 into ^b6351c. ↩
-
Don’t bother working out the maths in detail. Since the condition is intratemporal, ignore savings altogether from the original objective function. ↩
-
See the pseudo-utility function as a technique to transform the Ramsey Problem into a recursive maximization problem. ↩
-
This holds only approximately as we’re considering a “average” interest rate, also based on the Arrow security simplification. It would be exact if we set the rate dependent on the entire history of shocks. ↩
-
The outside option could also be endogenized. For example, the outside option could be a “new union”, where the history , which is also a solution to the PC problem. In this case, the outside option depends on the solution of another optimal problem. ↩
-
In this case, Dynare performs reasonably well, as the constraint features an equality rather than inequality. ↩
-
For additional reference, check an Aguiar and Gopinath paper on the topic. Their model features “too little commitment”, in a way. Although it can be argued that Albert’s paper involves too much commitment, the sweet spot is probably somewhere in between. ↩
-
A chapter on the topic is also included in Ljungqvist and Sargent. ↩
-
Although this looks natural, game theorists might contend that sequential Stackelberg equilibria might exist, alongside the recursive Nash equilibrium. ↩